Обзор книги “System Design Interview: An Insider’s Guide” — Part 1
Недавно я внимательно прочитал книгу “System Design Interview” за авторством Alex Xu. Книгу я изучал с практическим интересом, сфокусировав внимание на предложенном алгоритме прохождения System Design Interview и дальше на разобранных задачах. Мой интерес был связан с тем, что я курирую проведение таких интервью в Tinkoff и поэтому я хотел понять что и как преподносится в этом гайде. Про предложенный фреймворк я уже писал в отдельной статье, а сегодня мы обсудим первую половину книги, а в следующей статье вторую половину.

Книга состоит из 16 глав, из которых
— Первые три дают базовые знания
— Следующий 12 посвящены отдельным задачам
— И финальная глава приводит список источников для дальнейшего изучения
В этой статье мы поговорим только про первые семь глав, которые выделены оранжевым на изображении ниже.

1. Scale from zero to millions of users
В этой главе автор начинает с рассмотрения размещения системы на одном сервере и рассказывает про
— Базовую работу интернета (DNS, HTTP, IP)
— Базы данных и их варианты
— Вертикальное и горизонтальное масштабирование в общем
— Принцип работы балансировщика нагрузки
— Репликации базы данных
— Добавление уровня кэширования
— Использования CDN для раздачи статики
— Stateful и Stateless архитектур
— Использование разных датацентров для повышения надежности
— Использования очередей для добавления асинхронности в систему
— Логи, метрики, мониторинг систем
— Вертикальное и горизонтальное масштабирование баз данных
И финализирует главу такой рекомендацией
Summary of how we scale our system to support millions of users:
• Keep web tier stateless
• Build redundancy at every tier
• Cache data as much as you can
• Support multiple data centers
• Host static assets in CDN
• Scale your data tier by sharding
• Split tiers into individual services
• Monitor your system and use automation tools
2. Back-of-the-envelope estimation
Эта глава совсем мала, так как в ней автор приводит всего три таблички и один пример приблизительного расчета нагрузки на Twitter в виде query per second и storage, необходимого для хранения твитов и медиа.
Первая табличка проводит соответствие между степенями двойки, которыми все измеряется в мире компьютеров и степенями десятки, которые привычны для людей, одновременно приводятся названия единиц на примере байтов.
Вторая табличка называется “Latency numbers every programmer should know” и при ее анонсе идет отсылка к Jeff Dean, Google Senior Fellow, который опубликовал ее изначально в 2010. Но тут я рекомендую посмотреть более новую версию из rule-of-thumb-latency-numbers-letter, которая тоже опубликована Google в их материалах для SRE. Из этой таблицы видна драматическая разница в таймингах разных операций.
Ну и последняя табличка в этой главе посвящена тому, как считать показатели доступности (availability), а именно если наш сервис должен быть доступен X, то сколько времени он может быть недоступен.
3. A framework for system design interviews
В этой главе автор рассказывает про фреймворк для прохождения System Design Interview. Подробнее я рассказывал про него в предыдущей статье, ну а здесь я просто приведу иллюстрацию с четырьмя шагами этого фреймворка.

4. Design a rate limiter
В этой главе автор предлагает спроектировать rate limiter. Это система, которая позволяет ограничить количество внешних запросов на ваши системы или наоборот вам ограничить количество исходящих запросов. В любом случае система предназначена для того, чтобы ограничить количество запросов каким-то лимитом. Для решения этой задачи есть целый ряд алгоритмов
— Token bucket
— Leaking bucket
— Fixed window counter
— Sliding window log
— Sliding window counter
Достаточно стандартным являются варианты с token и leaking bucket, например, они используются в computer networks для congestion control. Автор неплохо раскрыл каждый из упомянутых выше алгоритмов и дальше нарисовал такой дизайн для системы.
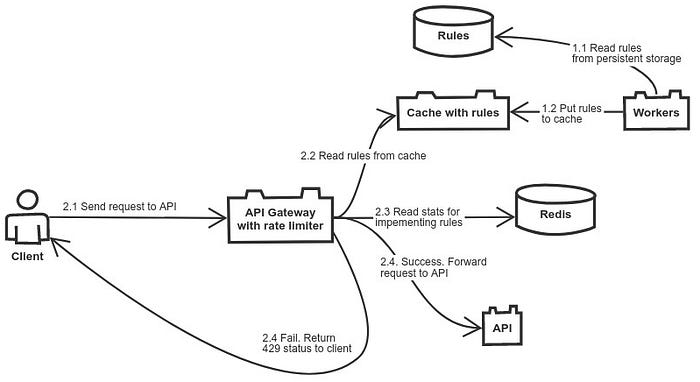
В итоге, мне имплементация rate limiter показалась скорее не отдельной задачей, а некоторым кубиком, который нужен в других задачах.
Хотя если заморочиться и спрашивать действительно глубоко, то это тоже может быть нетривиальной задачей. Например, можно почитать статью Yandex про их YARL: распределённый Rate Limiter с нулевым влиянием на время ответа сервисов.
5. Design consistent hashing
В этой главе автор рассказывает про один из consistent hashing — популярных механизмов для реализации горизонтального масштабирования посредством распределения запросов/данных равномерно по набору серверов. В wikipedia consistent hashing определяется так
A special kind of hashing technique such that when a hash table is resized, only n/m keys need to be remapped on average where n is the number of keys and m is the number of slots. In contrast, in most traditional hash tables, a change in the number of array slots causes nearly all keys to be remapped because the mapping between the keys and the slots is defined by a modular operation.
Интересно, что в этом подходе пространство ключей закольцовывается и дальше в рамках него происходит нарезка отрезков, за которые отвечает каждый сервер. А дальше добавляются виртуальные ноды. Про это можно кратко почитать в документации к Cassandra, в которой используется consistent hashing. И вот тут про использование virtual nodes и пример распределения данных с использованием virtual nodes
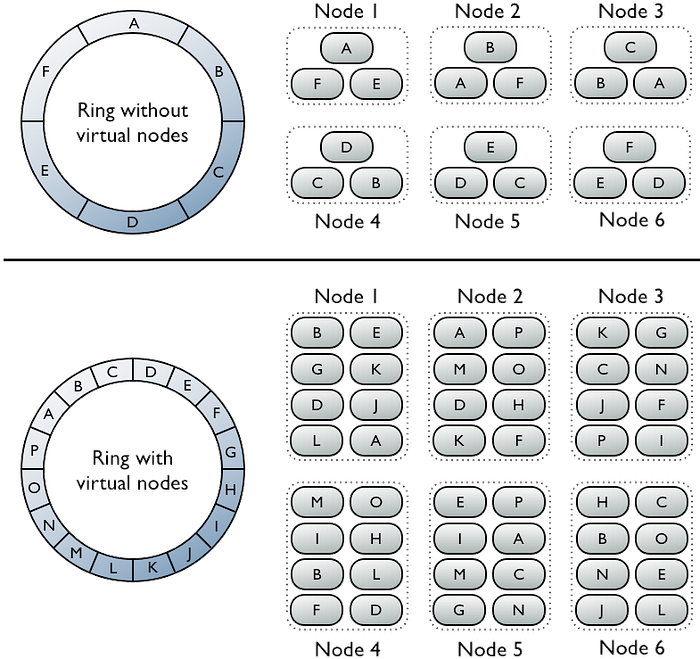
В общем, по-моему мнению эта задача тоже не тянет на отдельную задачку по System Design, но вполне может быть отдельным кубиком, который пригодится в других задачах и интервьюер определенно может спросить про этот вид хеширования.
6. Design a key-value store
В этой главе автор разбирает как спроектировать распределенное key-value хранилище, которое поддерживает 2 операции:
— put(key, value) // insert “value” associated with “key”
— get(key) // get “value” associated with “key”
Сомневаюсь, что в жизни вас попросят спроектировать такую систему, но вот понимать как работает key-value хранилище надо. Дизайн сильно зависит от требований к системе и автор фиксирует их так
— The size of a key-value pair is small: less than 10 KB.
— Ability to store big data.
— High availability: The system responds quickly, even during failures.
— High scalability: The system can be scaled to support large data set.
— Automatic scaling: The addition/deletion of servers should be automatic based on traffic.
— Tunable consistency.
— Low latency.
Если бы данные помещались на одну машину, то для решения можно было бы легко взять hash table, но к сожалению требование про возможность хранить большие данные мешает такому решению. Поэтому мы проваливаемся в царство распределенных систем и конкретно распределенных систем хранения данных. Про них отлично рассказано во второй части книги “Database Internals”, на которую я уже написал краткий обзор. Но в контексте этой задачи нам стоит знать про CAP теорему.
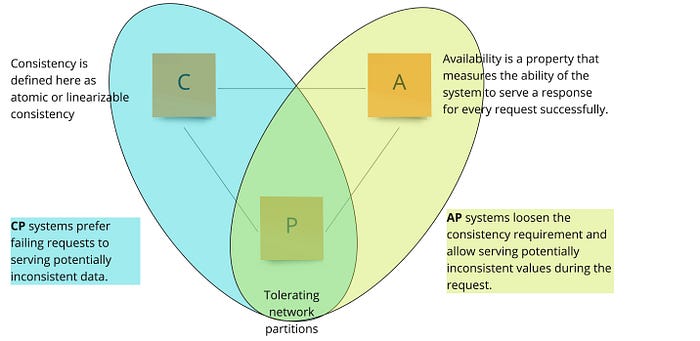
Для того, чтобы переживать отказы узлов у нас должна быть некоторая репликация данных по разным узлам. Так как разделение сети мы не можем предотвратить, то нам стоит выбрать как наша система ведет себя при таком событии. Она может быть
CP— система предпочитает не обслуживать часть запросов пользователей, но сохранять консистентность данныхAP— система ослабляет требования к консистентности, чтобы продолжать обслуживать запросы пользователей
Интересно, что у нас есть вторая проблема помимо обеспечения high availability, а именно big data. Для решения этой проблемы мы должны размещать ключи и значения ни на одной, пускай и реплицированной машине, а на большом количестве машин. Обычно такой подход называется sharding и для реализации горизонтального масштабирования посредством распределения запросов/данных равномерно по набору серверов мы можем использовать consistent hashing, который разобрали в предыдущей главе.
Дальше автор начинает рассказывать про консистентность вводя следующие модели
— Strong consistency: any read operation returns a value corresponding to the result of the most updated write data item. A client never sees out-of-date data.
— Weak consistency: subsequent read operations may not see the most updated value.
— Eventual consistency: this is a specific form of weak consistency. Given enough time, all updates are propagated, and all replicas are consistent.
Звучит неплохо, но на самом деле моделей консистентности чуть побольше и они чуть более точно формализованы. Их можно увидеть на рисунке ниже, где они приведены из второй части книги “Database Internals”, про которую я уже упоминал.
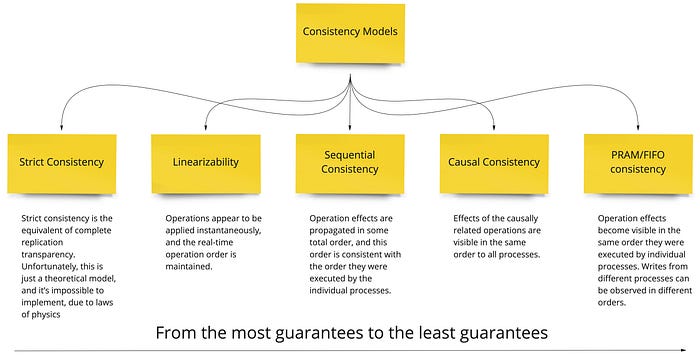
И если попытаться сопоставить описания Alex Xu из книги “System Design Interview: An Insider’s Guide” с общепринятыми, то strong consistency напоминает linearizability, а вот что такое weak consistency — это загадка. Ну а eventual consistency — это уже общепринятый термин.
Дальше Alex Xu начинает рассказывать про tunable consistency, когда при записи и чтении можно управлять фактором репликации, как показано на рисунке ниже
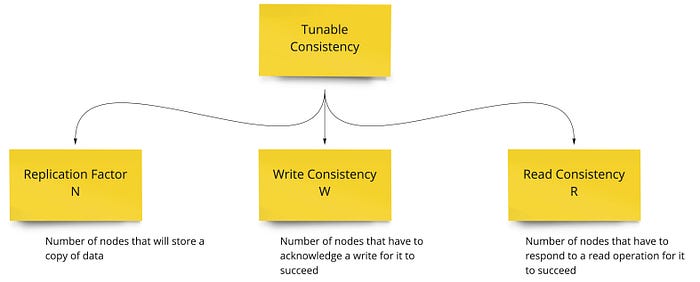
И дальше он говорит, что
If W + R > N, strong consistency is guaranteed (Usually N = 3, W = R = 2).
Забавно, что таких условиях не гарантирована линеаризуемость, поэтому я и говорил что strong consistency только напоминает linearizability. Подробнее рекомендую прочитать в блоге Yugabyte.
Дальше автор рассказывает про борьбу с неконсистентностью при записи и векторные часы Лэмпорта, которые можно использовать для реализации causal consistency. Но если конфликт при записи действительно происходит, то векторные часы не предлагают способа его разрешения и возлагают ответственность на клиента.
Дальше автор рассказывает про механизмы обработки ошибок и говорит о failure detection, среди которых самые простые варианты — это heartbeats и pings. Другие варианты из книги “Database Internals” представлены на рисунке ниже
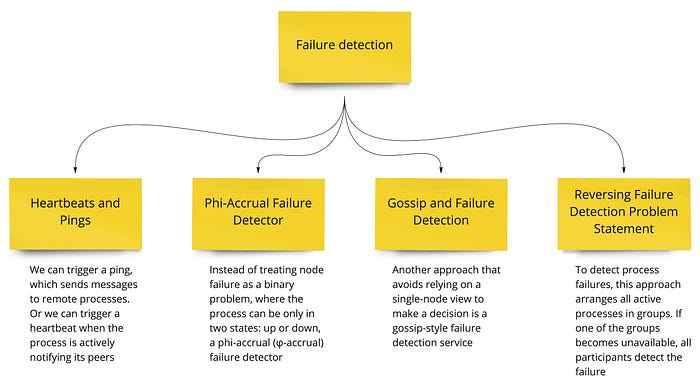
Помимо детекции ошибок есть еще механизмы борьбы с энтропией, про которые рассказывает Alex Xu
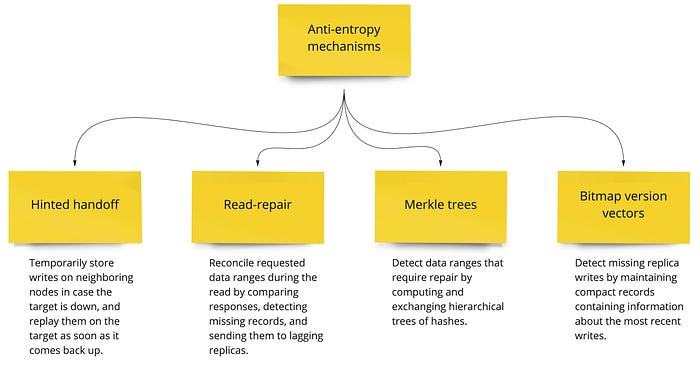
И напоследок автор упрощенно рассказывает про SSTable. Эта часть мне опять совсем не зашла и я рекомендую вам почитать первую часть “Database Internals”, в которой неплохо рассказывается про работу LSM (Log-Structured Merge Trees) хранилищ, в которых есть MemTable, SSTable и так далее. Схема на картинке ниже оттуда
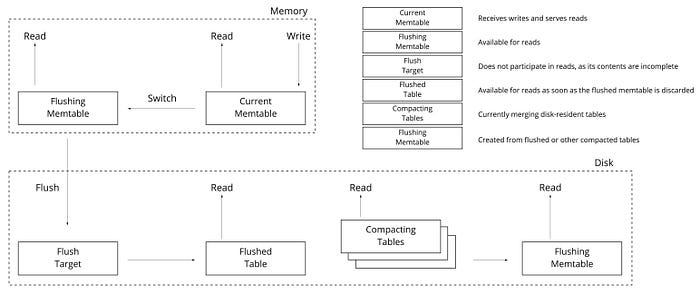
Если верить Wikipedia, то
LSM-дерево (журнально-структурированное дерево со слиянием) — это используемая во многих СУБД структура данных, предоставляющая быстрый доступ по индексу в условиях частых запросов на вставку (например, при хранении журналов транзакций).LSM-деревья, как и другие деревья, хранят пары «ключ — значение».LSM-дерево поддерживает две или более различные структуры, каждая из которых оптимизирована под устройство, в котором она будет храниться.
В общем, для того, чтобы спроектировать классный distributed key-value storage, требуется знать очень много теории:)
7. Design a unique id generator in distributed systems
В этой главе автор предлагает спроектировать решение для генерации уникальных идентификаторов. Конкретно автор фиксирует такие требования к решению
— IDs must be unique.
— IDs are numerical values only.
— IDs fit into 64-bit.
— IDs are ordered by date.
— Ability to generate over 10,000 unique IDs per second.
И дальше автор рассматривает четыре варианта генерации ID
— Multi-master replication
— Universally unique identifier (UUID)
— Ticket server
— Twitter snowflake approach
Multi-master replication
Используем опцию auto_increment внутри баз данных, но делаем k серверов баз данных и делаем так, чтобы они генерировали ID следующим образом
— Первый сервер генерирует значения 1, 1+k, 1+2k, 1+3k
— Второй сервер генерирует значения 2, 2+k, 2+2k, 2+3k
…
— k-ый сервер генерирует значения k, 2k, 3k, …
Подход выглядит достаточно просто, но имеет недостатки
—Сложно масштабировать с множеством датацентров
— Сгенерированные id не упорядочены по времени генерации, потому что сервера генерируют их независимо
— Сложно обрабатывать ситуации, когда добавляется или удаляется один из серверов
Universally unique identifier (UUID)
Согласно Wikipedia
UUID (англ. universally unique identifier «универсальный уникальный идентификатор») — стандарт идентификации, используемый в создании программного обеспечения, стандартизированный Open Software Foundation (OSF) как часть DCE — среды распределённых вычислений. Основное назначение UUID — это позволить распределённым системам уникально идентифицировать информацию без центра координации. Таким образом, любой может создать UUID и использовать его для идентификации чего-либо с приемлемым уровнем уверенности, что данный идентификатор непреднамеренно никогда не будет использован для чего-то ещё. Поэтому информация, помеченная с помощью UUID, может быть помещена позже в общую базу данных, без необходимости разрешения конфликта имен.
UUID представляет собой 16-байтный (128-битный) номер. В каноническом представлении UUID изображают в виде числа в шестнадцатеричной системе счисления, разделённого дефисами на пять групп в формате 8–4–4–4–12. Такое представление занимает 36 символов:
123e4567-e89b-12d3-a456–426655440000
xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
Структура UUID выглядит следующим образом

UUID обладает большими преимуществами в общем
— Генерировать такие идентификаторы просто и это не требует координации между серверами
— Систему с использованием таких идентификаторов легко масштабировать — каждая часть системы может сама себе генерировать UUID и масштабироваться как ей требуется
Но в контексте изначально поставленной задачи у такого способа создания идентификаторов есть и недостатки
— Идентификаторы имеют размер 128 bits, вместо 64 bits
— Идентификаторы не упорядочены по времени
— Идентификаторы не числа
Ticket server
Суть этого подхода в том, чтобы централизовать функцию генерации id в одном сервисе, к которому будут обращаться все остальные за получением уникальных идентификаторов.
Преимущества такого подхода в том, что его просто реализовать для небольших приложений, а минусы в том, что у нас появляется единая точка отказа (single point of failure)
Twitter snowflake approach
Этот подход к созданию идентификаторов анонсировал Twitter в далеком 2010 году в свое блоге. В Twitter этот подход используется для идентификаторов твитов. Про устройство формата можно прочитать и в Wikipedia — настолько он популярен. Вот как выглядит структура snowflake id

Описание формата из Wikipedia звучит так
— Snowflakes are 64 bits in binary. (Only 63 are used to fit in a signed integer.) — The first 41 bits are a timestamp, representing milliseconds since the chosen epoch.
— The next 10 bits represent a machine ID, preventing clashes.
— Twelve more bits represent a per-machine sequence number, to allow creation of multiple snowflakes in the same millisecond.
— The final number is generally serialized in decimal.
У snowflake ids есть определенные преимущества по сравнению с UUID
— snowflake id упорядочены по времени создания, поэтому они хороши для индексирования
— snowflake id в два раза короче, чем UUID
В общем, по-моему мнению эта задача тоже не тянет на отдельную задачку по System Design, но вполне может быть отдельным кубиком, который пригодится в других задачах и интервьюер определенно может спросить про то, как правильно генерировать уникальные идентификаторы.
P.S.
На этом эта статья заканчивается, а в следующей мы рассматриваем вторую часть книги и конкретно те задачи, которые действительно тянут на отдельные задачи в рамках System Design Interview.
