Собеседование SRE: Troubleshooting и System Design
В этот понедельник я выступал на конференции DevOps & Techlead Conf 2022 с темой вынесенной в название статьи. Я хотел рассказать про наш процесс найма SRE и два интересных этапа интервью, которые раньше проходили кандидаты, но потом остался только один:) Я могу рассказывать про это, так как я курирую секцию System Design Interview и провожу собеседования по Troubleshooting, которых в сумме набежало 150+ за последний календарный год. Кстати про System Design я уже рассказывал в нескольких статьях: 1, 2.

Для любителей движущихся картинок, а не лонгридов ниже приложена запись выступления
Мой рассказ начинается с рассказа о том, как сейчас у нас выглядит процесс найма Site Reliability Engineer. И он состоит из следующих этапов

Все начинается с ознакомительного общения с рекрутером, который выясняет стоит ли общаться дальше. Потом идут 3 технические секции
System Engineering— большой список вопросов в формате экспресс-опроса по темам, которые включают обсужденияhardware,networks,os,distributed systemsProgramming— решение нескольких простых задач, похожих на easy уровень сLeetCode. Здесь проверяется, что кандидат способен писать скрипты и способен разобраться с алгоритмической сложностью написанного кодаTroubleshooting— самый интересный этап, про который мы поговорим дальше подробнее
Если все ок, то кандидат, пройдя 3 технических секции, получает интегральную оценку и дальше о нем сообщают внутренним командам, которые находятся в самом верху очереди на найм. Дальше проходит Fit Interview с командой, после которого в случае успеха высылается оффер. Дальше мы поговорим подробнее про этап Troubleshooting, но начать стоит с вопроса

И ответ на этот вопрос следует из текущего этапа развития нашей компании
- 25+ млн клиентов — быстрый рост количества клиентов и нагрузки
- Мультипродуктовая компания — много отдельных бизнес-линий, платформ и сервис-линий со своими IT-подразделениями
- Продукты объединяются в экосистему — большое количество разнообразных нетривиальных интеграций между продуктами
- Быстрый рост штата — монолитные команды делятся на кросс-функциональные и автономные продуктовые команды
- Децентрализация обеспечения надежности систем — инженеры в командах должны сами уметь обеспечивать надежность своих систем
Ок, теперь мы знаем зачем это нужно компании, но надо ответить на вопрос, симметричный вышеуказанному, но для кандидата

Здесь ответ состоит из двух частей.
Первая причина — это возможность получить интересный опыт в работе над инцидентом в условиях приближенных к реальности. Обычно такой опыт можно получить только в условиях работы над реальной системой, когда цена ошибки достаточно велика. Здесь цена ошибки не так велика и можно проверить себя почти в «бою»
Вторая причина — это возможность получить или оффер разной степени крутости или обратную связь относительно того, что стоит подтянуть.
Ну а теперь когда мы поняли в чем цимес этого собеседования, нам пора поговорить о том, как оно выглядит.

Все шаги процесса представлены на рисунке ниже, ну а дальше мы обсудим их в деталях.

Интервью начинается с нулевого шага, а именно с описания регламента собеседования. По легенде кандидат и интервьюер работают совместно в SRE-команде. Кандидат исполняет роль Lead, а интервьюер — Junior. Собственно по той же легенде Lead уезжает на конференцию, а джуниор остается дежурить. А дальше происходит инцидент, который они вместе распутывают, так как Junior при старте инцидента сделал звонок другу (нашему кандидату) и попросил распутать инцидент совместно.
Но перед стартом инцидента есть еще два шага:
- Первый посвящен обсуждению архитектуры системы, которую поддерживает наша команда
SRE. Интервьюер показывает архитектурную схему и рассказывает про компоненты системы и взаимосвязи - Второй шаг — это вопросы кандидата по сути системы, часто кандидаты не задают уточняющие вопросы и сразу переходят к инциденту
На третьем шаге стартует инцидент, который сопровождается некоторыми внешними эффектами, похожими на симптомы болезни, которые интервьюер сообщает кандидату. Дальше мяч переходит на сторону кандидата и он ведет интервью, а интервьюер только отвечает на вопросы и применяет команды, которые отдает кандидат. Тут надо отметить, что и вопросы и команды должны быть максимально точными и конкретными, так как на сложные вопросы наш интервьюер Junior ответить не сможет в силу того, что он Junior:)
Четвертый шаг тянется почти до конца интервью — это история про непрерывную диагностику проблем при помощи формулирования гипотез и проведения экспериментов. Цель этого этапа в том, чтобы разобраться что не так и починить нашу систему.
Пятый шаг наступает, когда кандидат накапливает достаточно информации и понимания о ситуации, чтобы предложить workaround решение, которое поможет митигировать проблему для конечных пользователей системы и спокойно заняться раскапыванием проблемы дальше.
Шестой шаг — это полноценная починка проблемы, когда мы четко понимаем, что проблема устранена и она не вернется, если мы неловко двинем левой пяткой:) На этом шаге также важно рассказать как выглядит этот алгоритм починки, так как иногда кандидаты умудряются починить систему хаотичными движениями или хаотичным включением и отключением компонентов по заветам ребят из IT Crowd:)
На седьмом шаге кандидат добирается до root cause проблемы. У него собираются все элементы пазла в законченную картину и он способен объяснить почему все это произошло, почему наблюдались такие симптомы и почему отработал наш алгоритм починки.
Ну и финальный восьмой шаг посвящен тому, как улучшить нашу систему, чтобы в следующий раз наш Lead мог спокойно отдохнуть в отпуске. Для этого важно, чтобы
- Похожие проблемы не повторялись в будущем
- Или как минимум мы о них оперативно узнавали
Теперь мы разобрали шаги самого процесса интервью и интересно взглянуть на типовую задачу

Рассказ о типовой задаче конечно лучше глянуть в записи моего выступления, которая будет позже, но надо про нее рассказать и в статье. Такая базовая задача представлена ниже
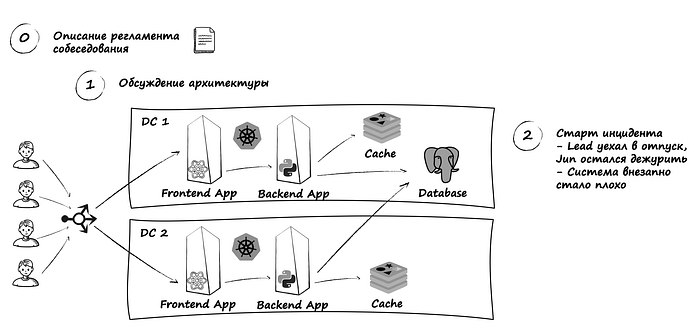
Все начинается с рассказа про регламент, который мы обсудили чуть раньше. Дальше идет обсуждение архитектуры нашей системы, у которой
- Несколько миллионов клиентов ежедневно
- Она развернут в двух датацентрах
- Приложение состоит из двух монолитных stateless компонентов: фронтовое приложение на
Reactи бекенд приложение наPythonDjango, которое предоставляетAPIдля фронтенда - Оба приложения развернуты в
K8sв виде нескольких инстансов - Слой данных представлен в виде персистентного хранилища
Postgresи кеша в видеRedis - Из изображения можно достать еще некоторые детали, но пора переходить к инциденту
Как заведено SRE Lead (наш кандидат) улетает в отпуск и на дежурстве остается Junior (наш интервьюер). Во время дежурства прибегает техподдержка и сообщает, что увеличилось количество обращений клиентов (по телефону или в чат поддержки) с жалобами на скорость работы сайта и периодически незагружающимися страницами. Наш интервьюер “звонит” кандидату и просит помочь с инцидентом.
Дальше я покажу как мог развиваться такой диалог (курсивом выделены ответы интервьюера)
- Есть ли у нас система для сбора логов, например,
ELKстек?
Да, у нас он есть, но я пока в нем ориентируюсь не слишком уверенно. Куда мне смотреть? - Давай посмотрим на визуализацию информации с логов балансировщика?
Открыл дашборд, что на нем искать? - Давай воспользуемся
RED Methodи поищем данные о количествеRequests,Errors,Duration?
Вижу, что количество запросов не увеличилось, но количество ошибок возросло и средний Duration запросов подрос. - А какой тип ошибок превалирует?
Летят ошибки разных типов, но большинство имеют статус 504 - Хмм, 504 — это
Gateway Timeout. Давай глянем в логи приложения …
В принципе, такой диалог продолжает идти плюс-минус на всем протяжении собеседования и кандидат пытается пройти все шаги, про которые я рассказывал, а интервьюер ему по мере сил помогает. Кстати, описанная выше часть диагностики приведена на рисунке ниже.

Теперь, когда мы знаем из каких этапов состоит Troubleshooting Interview и как выглядит типовая задача, нам пора переходить к вопросу оценивания кандидата.

Для оценки мы используем несколько критериев, представленных на рисунке ниже.

Таких факторов всего шесть
- Кругозор кандидата — нам важно оценить широту используемых инструментов и подходов к диагностике и починке системы
- Логичность и методичность поиска решения — нам важно, чтобы кандидат осмысленно шел по задаче, отсекая неверные гипотезы и приближаясь к починке системы
- Было ли найдено
workaroundрешение для быстрой митигации проблем у пользователей — этот пункт позволяет оценить насколько быстро кандидат сориентировался и устранил влияние на пользователей - Было ли найдено полноценное решение проблемы и удалось ли сформулировать алгоритм его применения — здесь нам важно, чтобы кандидат не остановился на костыльном варианте починки из предыдущего пункта, а действительно починил систему и сам понял как он это сделал
- Раскопали ли
root causeпроблемы, который объясняет исходные симптомы и почему алгоритм решения проблемы сработал — здесь важно, что кандидат понял в чем было дело, то есть докрутил ситуацию до логического конца - Предложены ли способы как улучшить систему, чтобы
— Похожие проблемы не повторялись в будущем
— Или как минимум мы о них оперативно узнавали
Здесь и так все ясно — мы хотим, чтобы кандидат по перефразированному правилу бойскаута оставлял после себя более надежную систему, чем та, что была до инцидента
Дальше важно показать как мы оцениваем кандидатов в соответствии с этими категориями




Правда, почти никогда не бывает таких ярко выраженных Junior, Middle, Senior или Senior+. Обычно оценки по разным осям варьируются. Посмотрим на рисунке ниже.

У этого кандидата неплохое знание инструментов и подходов (Middle), он достаточно логично шел по задаче (Middle+), быстро починил при помощи workaround решения (Middle), но не докопался до полноценного фикса проблемы(Junior), не понял в чем была корневая причина (Junior) и поэтому предложил косметические улучшения системы. В итоге, такой кандидат тянет на интегральный уровень Junior.
Интересно, что раньше у нас для SRE кандидатов был еще один этап в виде System Design, который очень сильно перекликается с последней характеристикой, где кандидат должен предложить способы улучшения системы. Но потом мы отказались от проведения System Design для SRE кандидатов. И дальше я хочу объяснить почему. Но для начала надо рассказать

Основные шаги System Design Interview приведены на рисунке ниже и про них можно узнать в моей статье “Дизайн секции как проверка навыков проектирования систем на собеседованиях”. Повторим их кратко в этой статье.

Все начинается с первого этапа, на котором интервьюер сообщает название задачи, дает дополнительный контекст и формулирует основные функциональные и нефункциональные требования. Дальше пульт управления собеседованием переходит к кандидату и именно он ведет собеседование (если может).
Второй шаг — это формализация задачи, в рамках которой кандидат должен задать вопросы интервьюеру, например, уточнить что именно должна позволять делать система. Важно определить, а что является ключевым для системы, например:
high availability(высокая доступность)data consistency(консистентность данных)high throughputscalabilityauditability
В общем и целом, тут могут быть любые архитектурные характеристики, многие из которых на английском языке оканчиваются на ilities. Подробнее про их важность я рассказывал в статье и выступлении “Эволюционная архитектура на практике”.
Кроме этого надо задать вопросы, которые позволят понять нагрузку на систему: сколько пользователей будет, как будет выглядеть нагрузка от них (количество запросов), сколько данных придется хранить и так далее. Важно не просто задать эти вопросы подряд, а подобрать их исходя из контекста задачи и, задав часть вопросов, сформулировать некоторые гипотезы о конкретных важных для системы числах. Именно эти данные нам потребуется использовать для проработки вопросов сайзинга системы.
Третьим этапом можно уже начинать проектировать систему и на этом шаге важно зафиксировать границы системы, какие сценарии мы должны реализовать и какое публичное API будет предоставлять система. На этом этапе система для нас представляется черным ящиком, но мы уже знаем что этот черный ящик обещает своим пользователям:) В общем и целом на этом этапе мы фактически строим System Context Diagram из C4 Model
A
System Contextdiagram provides a starting point, showing how the software system in scope fits into the world around it.
Четвертый этап самый интересный, так как именно на нем итеративно проектируется система. На этом этапе важно проработать потоки данных:
- как приходит запрос в нашу систему
- что мы с ним делаем — сохраняем в базу данных, закидываем в очередь, отправляем в
/dev/null - и так далее
По мере того, как мы прорабатываем поток данных у нас появляются компоненты системы, которые выполняют какие-то функции, которые требуются для реализации желаемого сценария.
Лучшая стратегия на данном этапе начинать прорабатывать happy path сценариев нашей системы, а потом возвращаться к exceptional flows и пытаться учесть их. Важно также не забывать про нефункциональные требования, например, такие, что мы не можем терять задачи пользователя и должны их выполнить за какое-то ограниченное время.
Именно на этом этапе важно проработать сайзинг системы на концептуальном уровне, то есть что систему при необходимости получится отмасштабировать под планируемые нагрузки. Например, стоит проверить, что самые нагруженные части горизонтально масштабируются и мы знаем как это сделать.
Теперь, когда мы знаем как выглядят оба собеседования, мы можем сравнить их между собой и понять почему осталось только одно.

Сравнение этих интервью приведено на рисунке ниже

Если говорить про Troubleshooting, то
- На старте уже есть боевая система
- Суть в том, чтобы потушить внезапно «загоревшуюся» систему
- Проверяем насколько системен подход к изучению симптомов, поиску временного лечения и дальше полноценному исцелению
- Хорошо проходят эту секцию ребята, которые близки к инфраструктуре и эксплуатации боевых систем
System Design чуть отличается
- На старте только требования заказчика
- Суть в том, чтобы спроектировать систему, которая не подвержена «возгораниям»
- Проверяем насколько системен подход к проектированию решения с учетом функциональных и нефункциональных требований и насколько жизнеспособная система получается в итоге
- Хорошо проходят ребята, которые близки к проектированию и разработке новой функциональности в сложных системах
Интересно, что в идеальном мире SRE должен обладать обоими навыками.

Это нужно, чтобы SRE мог не просто тушить пожары, но и системно работать над надежностью систем. Но реальный мир жесток и SRE кандидаты в среднем проходили System Design на уровень Junior, поэтому мы решили перестать спрашивать System Design
Правда, мы решили учить этому наших сотрудников, как разработчиков, так и SRE. Для прокачки в обеих областях, я бы изучал и теорию и практиковался

Если говорить про Troubleshooting, то
- Теория предполагает
— Изучения практик и подходов, изложенных , например,SRE BookиSRE Workbook от GoogleиBuilding Secure & Reliable Systems
— Изучение инструментов для применения этих методов - А практику можно получить
— Работая вSREкоманде над реальными системами
— Разбирая публичные postmortems крупных и сложных систем
— Тренируясь вtroubleshootingна задачах, сделанных по мотивам postmortems
System Design чуть отличается
- Теория предполагает
— Изучения принципов проектирования распределенных систем
— Изучения основных классов систем, их сильных сторон и границ применимости - А практику можно получить
— Работая в роли архитектора над проектированием реальных систем
— Разбирая архитектуру крупных сложных систем (от Google, Meta,…)
— Тренируясь в решении архитектурных ката
Кажется на этом я закончил обещанную программу и рассказал о всем, что хотел, поэтому рекомендую напоследок материалы, которые позволят двигаться по приведенному выше плану прокачки:)
Источники
Troubleshooting
— Google SRE Book и конкретно глава “Monitoring Distributed Systems”
— Google SRE Workbook и конкретно глава “Postmortem Culture”
— Ультимативный сборник материалов по SRE-подготовке
— Book ”Release It” (second edition)
— Моя статья “Культура postmortems или как мы учимся на ̶с̶в̶о̶и̶х̶ факапах”
— Github Repo with list of postmortems
System Design
— Моя статья в общем про System Design Interview
— Моя статья про подготовку к System Design Interview
