Публичное System Design Interview на конференции C++ Russia 2022 (задача — лента видеохостинга)
Полгода назад меня позвали на C++ Russia 2022, чтобы провести публичное собеседование по system design. Это было достаточно необычно, так как я не имею отношения к C++. Правда, с другой стороны это достаточно логично, так как я курирую в Tinkoff этот вид собеседований. Я достаточно много сделал для формализации самого процесса этих собеседований, онбординга новых интервьюеров и публикации информации для кандидатов. Подробнее информацию про это интервью можно почитать в других статья:
— в общем про system design в Tinkoff
— про то, как мы оцениваем это интервью
— про то как к нему подготовиться
— публичное System Design Interview на конференции ArchDays 2022.
Запись собеседования доступна ниже, а дальше я расскажу как бы я решал эту задачу плюс/минус в условиях близких к тому, что бывает на собеседованиях.
Надо отдельно отметить, что эту задачу я бы решал итеративно и эта пошаговость решения очень важна, так как проектирование сложной системы — это эволюционный процесс:) И его начальной точкой является
Описание задачи
Требуется спроектировать приложение, которое будет позволять загружать видео создателям контента и просматривать это видео всем остальным. Аналоги всем известны.
Функциональные требования
Нам требуется спроектировать сервис, которые позволит реализовать следующие фичи
- Система должна позволять создателям каналов быстро заливать видео
- Видео должно по готовности попадать в ленты подписчиков каналов
- Зрители должны иметь возможность поменять качество видео при просмотре
Нефункциональные требования
Решение должно обладать следующими архитектурными характеристиками
- Система должна обладать высокой доступностью
- Система должна быть масштабируемой и отказоустойчивой
- Мы должны по возможности обеспечить низкие затраты на инфраструктуру сервиса
Решение задачи
Первым делом, получая такую задачу, стоит заняться ее формализацией и задать вопросы по непонятным моментам. Чтобы у нас появилось понимание того, какую систему надо спроектировать и какие к ней есть требования помимо указанных прямо в условии. Отдельно стоит добавить
Правильно заданный вопрос — это половина ответа
Но для того, чтобы научиться правильно задавать вопросы, надо иметь опыт и хорошо понимать распределенные системы и где потенциально могут возникнуть потенциально проблемы. В общем и целом, обсуждение того, как понять какие вопросы задавать мы оставим на одну из следующих статей, а в этой я скорее покажу на примере, что можно спросить конкретно в этой задаче.
Формализация задачи
В этой задаче мне было бы интересно задать следующие вопросы для уточнения требований (ответы интервьюера я буду отмечать курсивом)
- Надо ли нам учитывать аутентификацию и авторизацию клиентов?
Нет, она тут достаточно типовая и лучше не тратить на нее время - Можем ли мы использовать внешние сервисы, например,
CDNдля раздачи контента?
Да, можем, если обоснуем зачем они нам нужны и как мы будем с ними взаимодействовать. Конкретно по поводу CDN могу сказать, что создание полноценной CDN тянет на отдельную задачу по System Design - Будем ли мы глубоко копать в транскодирование видео?
Нет не будем, так как это уже достаточно специфичный домен и у нас нет цели проверять у всех кандидатов их знания - В какие разрешения нам стоит конвертировать видео?
Допустим в 360, 480, 720, 1080 - Оригинальное видео сохраняем после всех конвертаций или нет?
Оригинальное видео будем удалять после всех конвертаций - Видео должно становиться доступным у подписчиков когда все разрешения готовы или хотя бы одно?
Видео будет становиться доступным после того, как все разрешения будут подготовлены - Ленты подписчиков формируются умным образом или это просто последние видео, добавленные авторами, на которых мы подписаны
Пускай ленты в нашем случае будут простыми с сортировкой по времени от самых последних к самым ранним, ленту мы будем получать порциями по 10 элементов
Отдельно зададим вопросы по нагрузке, которые влияют на то как нам потребуется масштабировать нашу систему:
- Какое количество пользователей у нашего сервиса мы ожидаем?
DAU (Daily Active Users) нашего сервиса будет 10 mln - Наши пользователи географически распределены?
Да, они расположены в разных регионах - Сколько видео в день будут смотреть наши пользователи?
В среднем 10 видео в день - Сколько видео в день будет загружаться
В среднем пользователи загружают по 0.1 видео в день - Какой средний размер видео будет загружаться в наш сервис?
Средний размер видео будет 300 Mb - Как часто пользователи будут запрашивать свой feed с видео?
В среднем 5 раз в день - Сколько храним загруженное видео
Время хранения не ограничено сверху
Теперь когда мы собрали требования по нагрузке, мы можем оценить какого масштаба будет наша система — это напрямую влияет на наши подходы к ее проектированию. А это значит, что нам стоит сделать базовые вычисления
- Количество просмотров видео — 10⁷ * 10 = 10⁸
- Дневной трафик на
download— 10⁸ * 300 Mb = 30 Pb - Полоса пропускания на
download— 30Pb / 86400 = 43.4 Gbyte/sec - Количество загружаемых в день видео — 10⁷ * 0.1 = 10⁶
- Количество загружаемых в секунду видео — 10⁶ / 86400 ~12 rps
- Количество запросов
feedв секунду — 5*10⁷ / 86400 ~ 580 rps - Дневной трафик на
upload— 10⁶ * 300 Mb =300 Tb - Нам надо будет хранить оригинальные видео пока мы не подготовим видео в нужных разрешениях, потом изначальное видео можно будет удалять — в итоге, нам надо будет
— относительно постоянное по размеру буферное хранилище для оригинальных видео, возьмем с запасом 1 Pb
— и постоянно расширяемое хранилище под конвертированное видео, пускай все конвертированное видео в сумме весит как оригинальное — тогда нам надо увеличивать хранилище со скоростью 300 Tb в день
В общем, у нас будет действительно масштабная система. Дальше будет полезно проговорить
Границы системы
Нам надо точно очертить что именно попадет в границы задачи и еще важнее что не попадает. Характерной чертой хорошо выстроенных границ является понимание основных сценариев работы системы и четко формализованного API.
На первый взгляд, в данной системе есть следующие границы
- API для заливки видео автором канала
- Нотификация автора о том, что видео готово
- Нотификация подписчиков канала о новом видео
- API для получения пользователем ленты видео, составленного на основе подписок на каналы
- Получение бинарного потока с конкретным видео
Теперь самое время нарисовать эти границы и базово их специфицировать. У меня сходу получилось что-то такое.
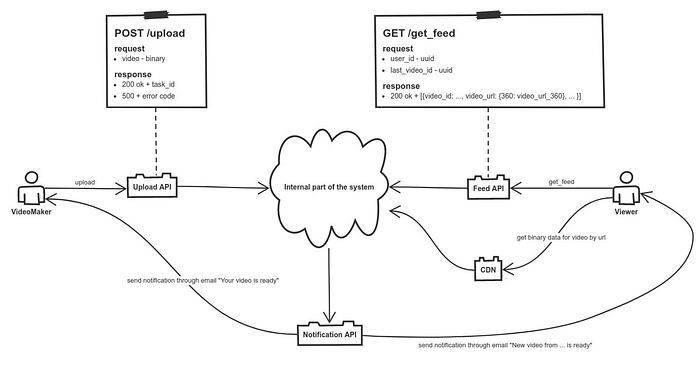
Кстати, в конце статьи будет ссылка на рисунки в хорошем качестве, которые приводятся в этой статье и которые безбожно сжимает сам Medium.
В нашем случае важно отметить, что основная write path происходит асинхронно — создатель видео (VideoMaker) заливает файл и он знает, что его обработка будет занимать некоторое время. Дальше по готовности оповещается как создатель видео, так и зрители, подписанные на видео данного автора. Другой сценарий получения информации о видео — это обращение зрителя за своей лентой доступных видео. И в оповещениях зрителей и в ленте доступны url видео, который будет обрабатываться CDN, которая за конкретным файлом будет ходить в нашу систему (внутри которой будет blob storage хранилище).
Этого вполне достаточно для того, чтобы перейти к следующему шагу и заглянуть внутрь системы, чтобы обсудить ее
Основной поток работы
Здесь проще всего взять основной сценарий и начать с него. В этой задаче это upload video, где создатель видео вызывает наш upload api передавая бинарный файл. Наш API должен сохранить оригинальное видео в blob storage, дальше сохранить задачу на конвертирование видео в нужные разрешения и вернуть клиенту task id.
Дальше нам нужны video conversion workers, которые разгребают задачи, скачивают оригинальное видео из blob storage, а дальше конвертируют видео и раскладывают готовые видео в отдельный blob storage и дальше сохраняется метаинформация о готовом видео. После этого в очередь открывается сообщение о том, что видео готово. Эту очередь разгребают 2 разных workers:
- Первый — это
notification workerи он отправляет нотификации о готовности видео автору и его подписчикам черезnotification service - Второй — это
feed worker, который будут готовить ленты для подписчиков и складывать ее вfeed database
Другой сценарий — это получение ленты видео каналов, на которые подписан пользователь. Данный сценарий начинается с обращения к feed api, которое делает запрос к feed database, где хранятся ленты пользователей.
Ну и последний сценарий — это просмотр видео, который происходит при обращении к cdn, которая раздает видео из своего локального кеша или, если видео еще не в кеше, то идет в blob storage, где лежат сконвертированные видео.
В итоге, получилось что-то из серии изображенного ниже.
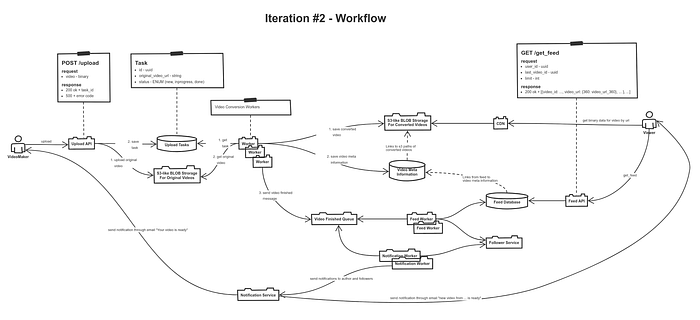
Концептуальная схема системы
Здесь нам надо поговорить про
- Классы кубиков, из которых состоит система
- Модели данных, которые хранятся в этих кубиках и/или путешествуют между ними
Давайте начнем опять с основного сценария upload video. Во-первых, в нашей схеме с основным потоком работы не было учтено, что наше upload api — это сервис, который должен быть развернут в нескольких инстансов для отказоустойчивости и масштабируемости. Эти экземпляры сервиса должны быть прикрыты общим балансировщиком нагрузки. Во-вторых, складывать исходные задачи в базу данных — это конечно один из вариантов, но он не слишком оптимален для планируемых нагрузок. Вместо него лучше поставить message queue, с семантикой at least once и возможностью делать подтверждение обработки per message (как можно в условном RabbitMQ), а не двигать offset (как принято в Kafka). В-третьих, теперь worker, при разгребании этой очереди с оригинальными задачами, не сразу начинает заниматься конвертацией, а делает 4 отдельные задачи на конвертацию в конкретные разрешения: 360p, 480p, 720p, 1080p, закидывает эти задачи в отдельные очереди на конвертацию, а дальше делает ack оригинальной задачи.
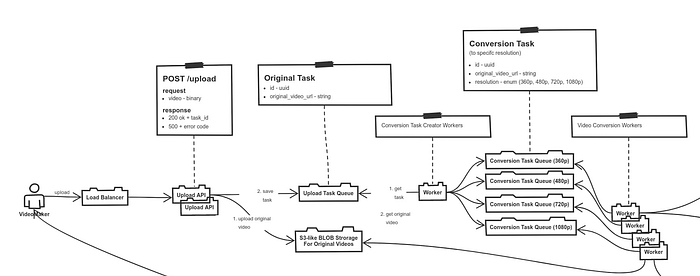
Дальше, в рамках этой части решения задачи, надо пробежать по всем компонентам системы и рассказать, какие там данные будут лежать и какой это будет класс системы:
- У нас есть
statelessсервисы, например,workers,api - У нас есть
blob storageдля хранения бинарных данных - У нас есть
messagequeue для хранения сообщений - У нас есть несколько баз данных для
— хранения метаинформации по загруженным видео
— хранения информации по лентам подписок - У нас есть внешние сервисы, которыми мы просто пользуемся
— этоfollower service, который мы используем для получения информации о подписках
— этоnotification service, который мы используем для отправки нотификаций авторам загружаемого видео и его подписчикам
— этоcdn, который мы используем для раздачи бинарных данных видео уже конечным пользователям
По всем компонентам все более-менее ясно, кроме баз данных, для которых сначала надо понять, какие данные там будут храниться. Начнем с данных о видео.
При загрузке, помимо самого бинарного файла, автор, как правило, добавляет название видео и его описание, давайте на этом и остановимся. Кстати, при этом нам надо подправить сигнатуру api метода upload, добавив прием этих параметров:) Ну да ладно, главное, что в хранилище метаинформации о видео будет информация вида:
Video
— uuid # id видео
— author_id # id автор
— title # название
— description # описание
— 360p_path # ссылка на версию в разрешении 360p
— 480p_path # ссылка на версию в разрешении 480p
— 720p_path # ссылка на версию в разрешении 720p
— 1080p_path # ссылка на версию в разрешении 1080p
— created_at # когда было создано
— updated_at # когда было обновлено
А при хранении ленты подписок у нас должна быть приблизительно следующая модель
Feed
— user_id # владелец ленты
— feed # массив id видео, которые относятся к ленте пользователя
В итоге, у нас есть модели данных и хоть между ними есть определенные отношения, но для лучшей масштабируемости эти данные мы будем хранить в условных key/value или документо-ориентированных базах данных (document-oriented database)
На текущий момент схема получилась следующей
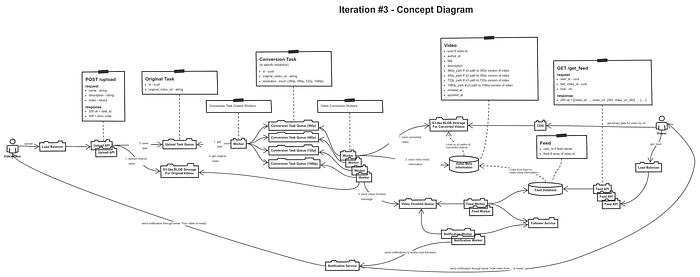
Реальная схема и масштабирование под нагрузку
Относительно реальной схемы пробежимся по порядку
load balancer — это достаточно стандартный компонент, у которого есть разница балансировать на уровне L4 или L7. Для первого варианта стандартная on-prem версия — это HAProxy, а для второго — Nginx, но вообще вариантов может быть много. Обычно это инфраструктурный компонент, на масштабирование и отказоустойчивость которого можно положиться, так как он предоставляется как сервис внутри организации
upload api, feed api— это просто stateless сервисы на языке, который нам нравится. Количество запросов на upload api при равномерной дневной нагрузке порядка 12 rps, а на feed api — 580 rps. В принципе, если нагрузка неравномерная, то интересно прикрутить аналог HPA (horizontal pod autoscaler) из K8s для горизонтального масштабирования инстансов нашего приложения в зависимости от нагрузки
blob storage — это хранилища оригинальных видео и уже сконвертированных. Здесь мы пользуемся хранилищем, поддерживающим S3 API, которое под капотом масштабируется под наши нагрузки. В облаке это может быть оригинальный S3, а в on-prem инсталляции MinIO или Ceph. В любом случае обычно это инфраструктурный компонент, на масштабирование и отказоустойчивость которого можно положиться, так как он предоставляется как сервис внутри организации
queues — для нашего паттерна использования нам нужен именно message broker (условно Rabbit MQ), а не log-based message queue (типа Kafka). Мы знаем какой у нас будет поток сообщений ~ 12 новых сообщений об upload видео в секунду, ~ 50 новых сообщений на конвертацию (12 * 4 вида разрешений). В общем, объемы кажутся достаточно небольшими. Плюс обычно queue — это инфраструктурный компонент, на масштабирование и отказоустойчивость которого можно положиться, так как он предоставляется как сервис внутри организации.
workers — это тоже stateless сервисы, которые удобно было бы масштабировать исходя из глубины очереди на обработку.
video meta information storage и feed storage — здесь нам хорошо бы выбрать хранилище, где мы можем хранить key/value или документы и которое под капотом умеет автоматический шардинг. Шардинг нам будет нужен, так как у нас большое количество видео и большое количество лент пользователей, поэтому все в одну машинку не поместится. Шардинг нам нужен в одном случае по ключу video_id, а во втором user_id — это мы определяем исходя из того способа, как мы планируем забирать данные, так как мы не хотим чтобы наши запросы были типа scatter gather и требовали обхода всех шардов. Конкретную базу можно, которая удовлетворяет нашим пожеланиям, оставляю здесь на ваш выбор.
Дополнительные вопросы
Почти в любой задаче обычно есть дополнительные вопросы, до которых доходит дело, если остается время после решения основной части задачи. Например, в нашей задаче может быть интересно обсудить очень популярные каналы и как в таком случае обновляются ленты подписчиков. Но обычно на подробное обсуждение дополнительных вопросов не хватает времени и максимум можно успеть обсудить основную концепцию:)
P.S.
Обычно мы стараемся оставить порядка 5 минут на вопросы кандидата, чтобы он мог спросить интервьюеров все что он хочет. Самые частые вопросы, которые я слышал
- “Зачем вы задаете такие задачи?”
- “Действительно ли придется внутри решать похожие задачи?”
- “В какую команду или в какой продукт меня смотрят?”
- “Как выглядит процесс работы внутри команд?”
Отвечу тут по пунктам
- На первый вопрос я подробно отвечал в статье в части “Зачем мы проверяем навыки дизайна систем?” и если сократить, то мы идем в сторону децентрализации принятия архитектурных решений — инженеры в командах должны сами уметь в проектирование систем
- Ответ на этот вопрос зависит от команды, куда попадет кандидат и сложности их задач, но с учетом ответа из первого пункта кажется, что архитектурные решения придется принимать в любом случае
- Это интересный вопрос, но на этапе
system design interviewна него не ответить, так как мы нанимаем в компанию, а не в команду — это значит, что узнать какая именно команда пригласит кандидата на финальное интервью можно будет только после прохождения всех технических секций - И этот вопрос сильно зависит от финальной команды, в которую попадет кандидат, но у нас дефолтом являются
agileподходы с выраженным продуктовым подходом в управлении как бизнес-продуктами, так и командами разработки
P.P.S
Внимательные читатели заметят, что мы не все изначальные требования выполнили в рамках нашей системы — обычно в реальном мире так и бывает и никто и никогда в рамках часового интервью не успевает закрыть все вопросы. Так что и в этой статье я хотел показать, что “не боги горшки обжигают” и что хорошая система сейчас лучше, чем идеальная когда-то:)
Итого у нас получилась какая-то итеративная схема, которую можно скачать в оригинальном качестве здесь.

