Как подготовиться и пройти System Design Interview
Собеседования в формате System Design Interview становятся все популярнее. Эти собеседования по проектированию проводят как для инженеров, так и для технических менеджеров, а их результаты влияют на оценку итогового уровня кандидата. В своем выступлении на ArchDays 2022 я рассказал о том, как подготовиться к таким собеседованиям и как себя проявить с лучшей стороны прямо на нем. Кстати, прямо в рамках этой конференции у меня было еще открытое из интервью, про которое я написал здесь, поэтому можно посмотреть как такое интервью выглядит на практике.

На самом деле про System Design я рассказывал уже раньше и э ту информацию можно прочитать в двух предыдущих статьях: в общем про system design в Tinkoff и больше про то, как к готовиться к этому собеседованию, а также проводил публичное System Design Interview на конференции C++ Russia 2022 и публичное System Design Interview на конференции ArchDays 2022. В этот раз я подошел к вопросу более фундаментально и расписал ожидания гораздо подробнее, а кроме того дал материалы для подготовки:)
Ниже представлена запись выступления, а потом идет его текстовая расшифровка.
Для начала вспомним, что у нас в Tinkoff интервью по System Design проводится для тех инженеров, что претендуют на позицию Senior. Также она проводится для всех технических руководителей, начиная с тимлидов и заканчивая CTO. Ниже на изображении перечислены наши стадии интервью и видно, что System Design Interview идет после собеседования по алгоритмам и языку программирования.

Теперь, когда мы знаем для кого предназначено System Design Interview, мы можем обсудить из каких шагов оно выглядит. В книге “System Design Interview” за авторством Alex Xu предлагается алгоритм, который состоит из четырех шагов

Я делал краткий обзор этого алгоритма в своей статье чуть ранее, а сегодня я хочу чуть глубже поговорить про свой фреймворк для прохождения System Design Interview. Мой фреймворк представлен на изображении ниже
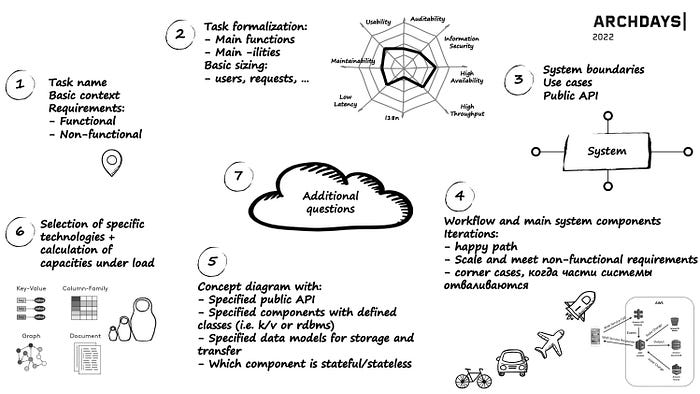
Этот фреймворк состоит из следующих этапов
- Первый этап, на котором сообщается название задачи и дается дополнительный контекст с перечислением основных функциональных и нефункциональных требований. На этом этапе больше говорит интервьюер, а дальше он замолкает и инициатива в дискуссии переходит к кандидату
- Второй этап — это этап формализация, в рамках которого кандидат задает вопросы интервьюеру, чтобы уточнить что именно должна позволять делать система, а также определяет ключевые архитектурные характеристики системы, например:
—high availability(высокая доступность)
—data consistency(консистентность данных)
—high throughput
—scalability
—auditability - Третий этап — этот этап посвящен проектированию границ системы, где мы должны зафиксировать публичное
APIдля всех сценариев системы - Четвертый этап — он самый интересный, так как на нем итеративно проектируется система. Причем нам важно проработать
happy pathиexceptional flows. По мере того, как мы прорабатываем поток данных у нас появляются компоненты системы, которые выполняют какие-то функции, которые требуются для реализации желаемого сценария. - На пятом этапе у нас готова концептуальная схема и можем обсудить ее целиком. Все результаты с последних этапов сведены в одном месте и консистентны
- Шестой этап посвящен выбору конкретных технологий и обсуждению
sizingсистемы с учетом этого выбора. На этом этапе можно продемонстрировать знание современных решений и то, что у нас получится с ними отмасштабировать систему под планируемые нагрузки. - На седьмом этапе появляется время обсудить дополнительные вопросы, которые часто расширяют
scopeсистемы или усложняют нефункциональные требования. Эта часть опциональна, но позволяет хорошему кандидату продемонстрировать свои широкие знания и умения.
Теперь, когда мы знаем в чем суть интервью, мы можем перейти к вопросу, а как подготовиться к интервью.

Пойдем по этапам и рассмотрим каждый из них в разрезе что стоит знать и уметь для успешной работы на этом этапе, а также что можно изучить, чтобы этому научиться и начнем с этапа
Формализация
На этом этапе важнее всего уметь задавать правильные вопросы, чтобы уточнить что входит в scope задачи, а что можно благополучно вынести за скобки. Дальше желательно уметь собирать функциональные требования в виде желаемых сценариев системы, которые она должна реализовывать. Кроме этого классно иметь опыт выяснения нефункциональных требований и составления таблички самых важных архитектурных характеристик. Здесь потребуется умение определения сравнительной важности этих требований между собой — не все функциональные требования одинаково важны и часто самое сложное из них требуется проработать лучше всего. Аналогично по архитектурным характеристикам — иногда они противоречат друг другу и нам надо знать каким из них надо отдать приоритет даже в ущерб другим.
Теперь перейдем к рекомендациям для этого этапа — что изучить и почитать, чтобы уметь лучше понимать какую задачу мы решаем. Для формализации функциональных требований можно изучить подходы
Use Cases из UML — помню как я 15 лет назад, изучая UML, наткнулся на этот подход и он мне показался достаточно здравым. В этом подходе есть actors, systems и список интересных нам сценариев. Интересно, что в этом подходе сценарии — это текстовые описания, в которых фиксирован happy path и exceptional flows, которые позволяют понять как должен работать этот сценарий
User story — это более неформальный подход, который тоже про сценарии, но скорее с точки зрения end user и полезной для него фичи. Стандартный шаблон для описания истории выглядит так
As a <role> I can <capability>, so that <receive benefit>
Jobs to be Done — этот подход сейчас достаточно популярен. В нем один и тот же продукт разные пользователи приобретают для различных целей. Или, как принято говорить в терминологии JTBD, нанимают на работу. В общем, в этом подходе мы исходим из того, какой результат и в каком контексте хочет получить пользователь от системы, то есть в парадигме “работы, которая должна быть сделана” системой.
Для сбора и анализа нефункциональных требований рекомендую изучить базово Architecture Tradeoff Analysis Method на уровне погружения, который есть в книге “Software Architecture for Busy Developers”, про которую я писал раньше в обзоре. И конкретно оттуда рекомендую прочесть часть про fit for purpose и fit for use
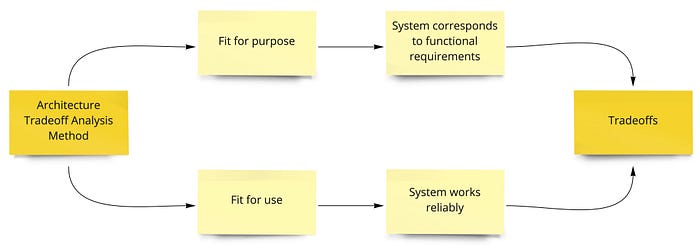
А также про
Sensitivity points—это решения которые влияют только на один атрибутTrade-off points— это архитектурные решения, которые влияют на несколько атрибутов и обычно при выборе мы жертвуем одним из них в пользу другогоRisksиNon-risks— это риски и возможности от архитектурных решений

Ну и завершая тему формализации я не могу не вспомнить крутейшую книгу Вигерса “Software Requirements. Third Edition”, которая в свое время здорово продвинула меня в понимании требований к программному обеспечению.
Границы системы
На этом этапе мы уже формализовали задачу, а значит знаем функциональные и нефункциональные требования, исходя из которых можем спроектировать как будут выглядеть границы системы и точки интеграции.
Здесь нам необходимо уметь выбирать правильный способ взаимодействия нашей системы с пользователями, а также вариантов интеграции нашей системы с внешними системами. Всего есть 4 варианта интеграции, про которые рассказывал Hohpe в книге ”Enterprise Integration Patterns” и вот они
— Files — интеграция через выгрузки файлов
— Database — интеграция через общую базу данных
— API — интеграция через API (самый удобный способ для большинства случаев)
— Messaging — интеграция через отправку и получения сообщений
Зная про эти способы, надо понимать их плюсы и минусы и выбирать тот способ, который является более подходящим для нашего случая. Если же мы выбираем интеграцию через API, то нам надо понимать какие там подходы существуют, например
— REST (OpenAPI)
— RPC (gRPC, JSON-RPC, …)
— GraphQL
— AsyncAPI
— …
Ну и конечно надо уметь описывать контракты в выбранном подходе.
Для того, чтобы лучше понимать границы системы я рекомендую изучить несколько тем. И пожалуй стоит начать с изучения System Context Diagram из C4 Model. Этот вид диаграмм отлично показывает границы нашей системы и точки взаимодействия.
Дальше стоит вспомнить, что наша система не висит отдельно в безвоздушном пространстве и из ниоткуда получает запросы пользователей. Нет, у нас есть связующая среда в виде сетевого слоя, про который часто забывают. Это бывает оправданно при обсуждении happy path сценарии, но когда что-то идет не так, то нам уже необходимо понимать как выглядит путь запросов целиком, включая сетевую конфигурацию. Поэтому я рекомендую вспомнить про
— Теоретическую сетевую модель OSI
— Практические сетевые протоколы UDP, TCP/IP
— Подход к разрешению имен DNS
— Протоколы application уровня
— — HTTP/HTTPS и разных версий: 1, 2, 3
— — Webscokets
— — …
Помимо сетевого уровня нам стоит помнить, что на входе обычно ставят балансировщики нагрузки (Nginx, HaProxy) и вообще подход Service Mesh:)
Ну и рекомендую прочитать 2 книги:
— Tannenbaum ”Computer Networks”
—Hohpe ”Enterprise Integration Patterns”
Основные потоки и компоненты системы
На этом этапе мы уже зафиксировали основные сценарии и границы системы и дальше нам надо проработать основной поток работы (happy path), проходящий через компоненты системы. Также стоит очертить exceptional flows и как наша система их обработает. Но самое важное здесь — это научиться определять read/write path для системы с учетом архитектурных характеристик, которые мы выявили на этапе формализации задачи.
Для того, чтобы лучше научиться это делать я рекомендую изучить
— Container Diagram из C4 Model
— Sequence Diagram и Activity Diagram из UML
— IDEF0 — подход к функциональному моделированию, достаточно старый и сейчас не слишком популярный, но полезный для расширения кругозора
— DFD — подход к описанию потока данных через процесс или систему. Сейчас подход не слишком популярный, но полезный для расширения кругозора
— BPMN — подход к описанию бизнес-процессов. Этот подход достаточно популярен и релевантен в текущее время
— Как балансировать read/write path для системы в книге Kleppmann “Designing Data-Intensive Applications”
Концептуальная схема
Здесь нам надо понять, а какими являются наши компоненты, то есть из каких кубиков собрана наша система. Про эти кубики как-то рассказывал Philippe Kruchten в своем выступлении “Software Architecture: A Mature Discipline?”.
В любом случае, наши кубики можно поделить на те, которые хранят состояние (stateful), и те, которые обходятся без этого (stateless). Суть в том, что работать со stateless компонентами проще, но их полезность ограничена, если рядом нет stateful компонентов, в которых хранится информация, которая нужна пользователям. Состояние бывает persistent и transient, но в любом случае нам надо уметь проектировать модели данных и структуры для их хранения.
Если мы говорим про то, где хранить данные, то мы должны уметь выбирать те инструменты, которые лучше подойдут для нашей ситуации. Я говорил про это в лекции из курса “Essential Architecture #Data”. И вот опорный слайд из того рассказа:)
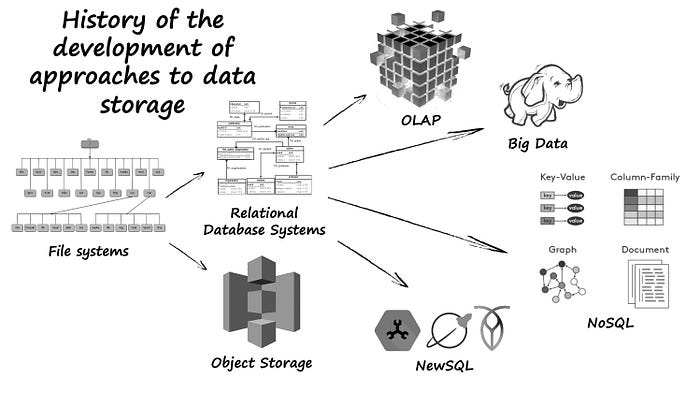
А теперь поговорим о том, что стоит изучить для того, чтобы уметь создавать концептуальную схему.
Начать стоит с того, чтобы изучить стратегические паттерны из Domain Driven Design, а именно какие subdomains бывают в организации, как их описывать при помощи ubiquitous language и как делить части системы на bounded context. Все это отлично описано в книге “Learning DDD”, про которую я уже много раз писал, например, здесь — уж больно она хороша.
Дальше стоит изучить подходы к моделированию данных, а именно ER diagram (entity relationship diagram), а также их вариация в рамках UML — Class Diagram. Это полезно для того, чтобы моделировать сущности и связи между ними, что напрямую следует из названия.
Дальше я рекомендую изучить подходы для создания stateless приложений, которые в свое время были собраны в манифесте The Twelve-Factor App. Помимо этого интересно посмотреть как эти подходы можно реализовать в рамках cloud native подхода с использованием оркестратора навроде Kubernetes, а об этом отлично написано в книге “K8s Patterns”.
Помимо этого я рекомендую почитать книгу “Software Architecture: The Hard parts”, потому что в ней много говориться о том, как организовывать взаимодействие компонентов системы с учетом их зон ответственности, а также что делать с данными.
Реальная схема и желаемые архитектурные характеристики
На этом этапе мы должны уметь выбирать конкретные решения из тех, что перечислены в нашей концептуальной схеме. Условно если мы указали, что нам нужна реляционная база данных, то мы должны знать какие они бывают, например, Postgres, Mysql, Oracle, … и главное мы можем взвешенно и аргументированно указать какая из них нам тут подойдет. Похожая история с системами для работы с сообщениями, например, мы должны выбрать что использовать ActiveMQ, Rabbit MQ, Kafka, Apache Pulsar или что-то еще, понимая их гарантии и сложности использования.
Другая важная история — это думать о системе в разрезе концепции failure domains, то есть что в нашей системе может отказать. Отказать на уровне сервиса, машины, зоны доступности или целого датацентра.
Ну и в реальной жизни стоит помнить, что помимо создания системы у нас есть day-2 operations, а именно эксплуатация системы и дальнейшее ее развитие. В рамках эксплуатации важно понимать а что происходит с системой при ее работы, то есть на первый план выходят вопросы логирования, мониторинга и так далее. А вот вопросы развития системы связаны с тем насколько она понятна и не переусложнена и декомпозирована на отдельные автономные части.
А теперь поговорим о том, что стоит изучить для того, чтобы уметь создавать размышлять о реальной схеме.
Для того, чтобы эффективно размышлять о технологиях, требуется их потрогать в реальности. Начать с изучения документации, потом потрогать их руками, развернув в тестовом окружении и поиграв с основными сценариями. Сейчас это сделать просто как никогда — у нас есть облака, где поднять виртуалку с нужным образом проще простого. Часть сценариев можно проверить, поиграв с managed версиями сервисов, которые облачные провайдеры поддерживают вместо вас.
В результате таких экспериментов у вас сложится представление о том, что умеют эти системы, на какой диапазон нагрузок они рассчитаны (условно rps per cpu) и насколько легко и просто ими пользоваться. Отдельно уточню, что сценарии из базовых мануалов этих систем могут выглядеть просто, но под капотом может скрываться множество нюансов.
Отдельно я рекомендую изучить SRE подходы, которые последние годы популяризируют Google, рассказывая о том, как они работают над надежностью своих систем. Об этом можно узнать, прочитав книги
— Building Secure and Reliable Systems
— SRE book
— SRE Workbook
Первую из этих книг я рекомендую прочитать обязательно, так как первая половина книги посвящена тому, как проектировать надежные и безопасные системы с самого начала, потому как добавить надежность или безопасность в существующую систему может стоить на порядок дороже:)
Масштабирование под нагрузку
Здесь нам надо уметь масштабировать наше решение. Для stateless компонент сейчас стандартным способом является использование оркестратора, например, Kubernetes, в котором есть возможность для вертикального (VPA) и горизонтального (HPA) масштабирования. Настроить это масштабирование можно по разному, например
per-pod resource metrics (like CPU), ориентируясь на утилизациюper-pod custom metrics, ориентируясь наraw valuesobject metrics and external metrics, например, глубина очереди, которую разгребают наши поды-воркеры
Более сложный вариант — это вопрос масштабирования stateful компонент. Здесь сразу возникает вопрос, а что мы хотим масштабировать
— Масштабировать чтения — тогда мы можем использовать концепцию кеширования, но у нас сразу возникает вопрос консистентности кеша и его инвалидации. Также мы можем использовать репликацию и читать с secondary реплик, но здесь в зависимости от реализации могут быть ослаблены требования по consistency.
— Масштабировать записи — здесь мы можем использовать концепцию partitioning и sharding, но нам надо знать паттерн доступа к данным, чтобы такая схема работала
Для того, чтобы все это освоить придется потратить много времени на изучение теории и эксперименты, но начать следует с чтения книги Kleppmann “Designing Data-Intensive Applications”, а потом почитать книги: Tanenbaum “Distributed Systems”, Petrov “Database Internals” и Ibryam “K8s Patterns”.
На этом советы по подготовке к интервью заканчиваются и остается обсудить только
Советы для успешного прохождения интервью
Я их собрал в короткий список, который как мне кажется, повышает эффективность прохождения интервью и вероятность того, что вы сможете показать свои лучшие стороны
— Помнить о времени — время интервью обычно ограничено часом и за него надо успеть многое обсудить. Именно поэтому не стоит закапываться в какие-то детали, а контролировать тайминг и двигаться по решению задачи
— Не начинать проектировать сразу — важно четко понять задачу и только тогда начинать ее решать. Если у вас есть вопросы после прочтения условий, то лучше сначала получить на них ответы, иначе можно начать не ту задачу, что вас попросили
— Делиться своими размышлениями при проектировании с интервьюером — этот тип собеседования нужен для того, чтобы понять как вы решаете сложные задачи и как мыслите при их решении. Если вы будете преимущественно молча рисовать схему и изредка рассказывать что вы нарисовали, то интервьюер не поймет всей глубины вашей задумки
— Проявлять самостоятельность в проектировании — это открытое интервью, где кандидат может проявить свои сильные стороны и показать как он проектирует. Но если интервьюеру придется вести кандидата по задаче, задавая структуру и помогая с решением, то это не добавит очков кандидату
— Реагировать на наводящие вопросы и уточнения — обычно интервьюер такими вопросами пытается навести кандидата на правильные мысли, когда он забуксовал
— Говорить уверенно о том, что знаешь, а не то — не стоит говорить о том, о чем только смутно слышал, так как интервьюер может поинтересоваться деталями и тогда кандидату придется краснеть …
— Подготовить вопросы к интервьюеру на случай, если для них останется время — это показывает то, что вам интересно узнать про компанию и происходящее в ней
На этом мой доклад заканчивается и остается только привести
Рекомендации для дальнейшего изучения
Статьи
—Статья про System Design Interview
— Статья про подготовку к System Design Interview
— Публичное System Design Interview на C++ Russia 2022
— Публичное System Design Interview на конференции ArchDays 2022
— Статья про то как развиваться Senior
— Стать про Troubleshooting Interview в Tinkoff
Книги
— Wiegers “Software Requirements. Third Edition”
— Eyskens “Software Architecture for Busy Developers”
— Tannenbaum ”Computer Networks”
— Tannenbaum “Distributed Systems”
— Hohpe ”Enterprise Integration Patterns”
— Kleppmann “Designing Data-Intensive Applications”
— Khononov ““Learning DDD””
— Petrov “Database Internals”
— Ibryam “K8s Patterns”
— Google ”Building secure and reliable systems”
— Google “SRE Book”
— Google “SRE Workbook”
